前期准备
VMware下载:
VMware14
链接:https://pan.baidu.com/s/1lrNwuUpmmFtRwnlUEim5RA
提取码:xqq0
密钥
FF31K-AHZD1-H8ETZ-8WWEZ-WUUVA
CV7T2-6WY5Q-48EWP-ZXY7X-QGUWD
VMware16(win10及以上版本建议装此版本)
链接:https://pan.baidu.com/s/1TQsTNVJqiPCnvVKIeY-UAg
提取码:fu6u
密钥
ZF3R0-FHED2-M80TY-8QYGC-NPKYF
YF390-0HF8P-M81RQ-2DXQE-M2UT6
ROS+Ubuntu16.04镜像(VMware):
初始化用户名:ros 密码:123456
链接:https://pan.baidu.com/s/1WORFJfr_llFCmywyNzVAZw?pwd=j2p2
提取码:j2p2
语音交互源代码下载
链接:https://pan.baidu.com/s/13nqlBSbhp8kZfVrlB1nJVg
提取码:1lyq
VMware Tools的安装
最大的好处是可以直接把windows界面的文件拖进linux虚拟机内
方法参考:https://blog.csdn.net/Williamcsj/article/details/121019391
重新启动虚拟机中的Ubuntu系统
将源代码文件夹压缩包ros_voice_system-master.tar.gz,复制到虚拟机/home目录下

1 | cd /home/ros/ |
解压操作也可以通过图形化界面,右键,提取压缩包中的文件
添加声卡
操作如下图所示,添加->声卡->完成


系统启动
安装语音相关软件包
打开一个终端执行脚本
1 | cd /home/ros/ros_voice_system-master/scripts |
此脚本安装缺少运行语音程序的软件包,编译整个代码空间,配置环境变量,可以说是一键执行脚本,减少大家烦琐的配置编译步骤。
执行过程中的warring提醒pip版本可用更新,请不予理会,pip更新后会导致版本不兼容
该过程根据网络情况不同,耗时10-40分钟
脚本运行结束后
编译启动
脚本已经相当完善,包含了环境变量配置,编译和启动功能,如需编译和启动参考以下命令
编译需要在ros工作空间根目录下执行,也就是在ros_voice_system-master
1 | catkin_make |
启动命令
1 | source devel/setup.bash |

在没有出现错误的前提下,如果唤无法唤醒,请一定要检查输入音量,不要设置过低,Ubuntu默认设置可能很低

如何还无法唤醒也不要着急,此代码有两套语音唤醒方案,后面会教大家如何更换配置。
如果现在就想唤醒体验一下,也可以暂时通过命令行唤醒,首先打开一个新终端,执行一下命令
1 | rostopic pub /voice_system/wakeup_topic std_msgs/String "data: '卡丁'" |
程序解读

该项目一共包含11个功能包,一般情况下只需修改launch和src目录下的代码文件
修改voice_bringup.launch 启动文件
该launch文件为ROS下语音系统的总启动文件,当运行加载启动后会自动的来启动语音唤醒,语音识别,语义理解,语音合成节点。需要注意的是这 里由于实现方案较多,现在实现的所有语音功能唤醒模块有sphinx和snowboy,语音识别用百度在线语音识别和科大讯飞在线语音识别功能实现,语义解析目前使用图灵机器人的在线语义解析实现,对于语音合成功能使用百度在线语音和科大讯飞在线语音合成实现,所有可用的节点都会在launch文件中列出,但是并不是所有节点都启动,若想启动相应节点去掉注释即可,因此现在规定 默认的启动节点如下所列:
1.语音唤醒(WakeUp):pocketsphinx离线语音唤醒,唤醒词:卡丁
2.语音识别(ASR):科大讯飞在线语音识别功能;
3.语义处理(NLP):图灵机器人在线语义处理;
4.语音合成(TTS):科大讯飞在线语音合成模块;
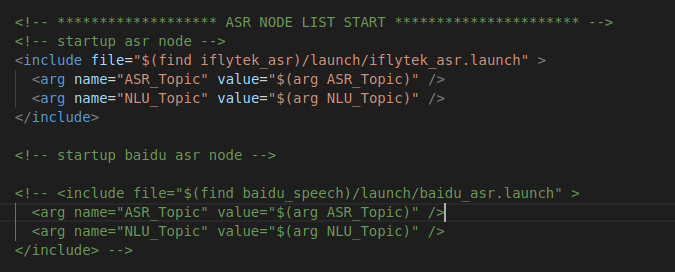
比如语音识别功能,配置了两套方案,如果选用科大讯飞语音识别(iflytek_asr),就需要把百度语音识别(baidu_asr)注释掉,避免冲突,其他功能配置方法同理
服务调用配置
目前启动起来的语音服务并不是使用的自己的配置,随时都有欠费停用的风险,一般开发平台新用户完成实名认证会有免费资源调用额度,以百度语音引擎为例,介绍配置过程
1.打开百度智能云官方网站https://cloud.baidu.com/
2.如果没有百度账号,需要先注册一个账号
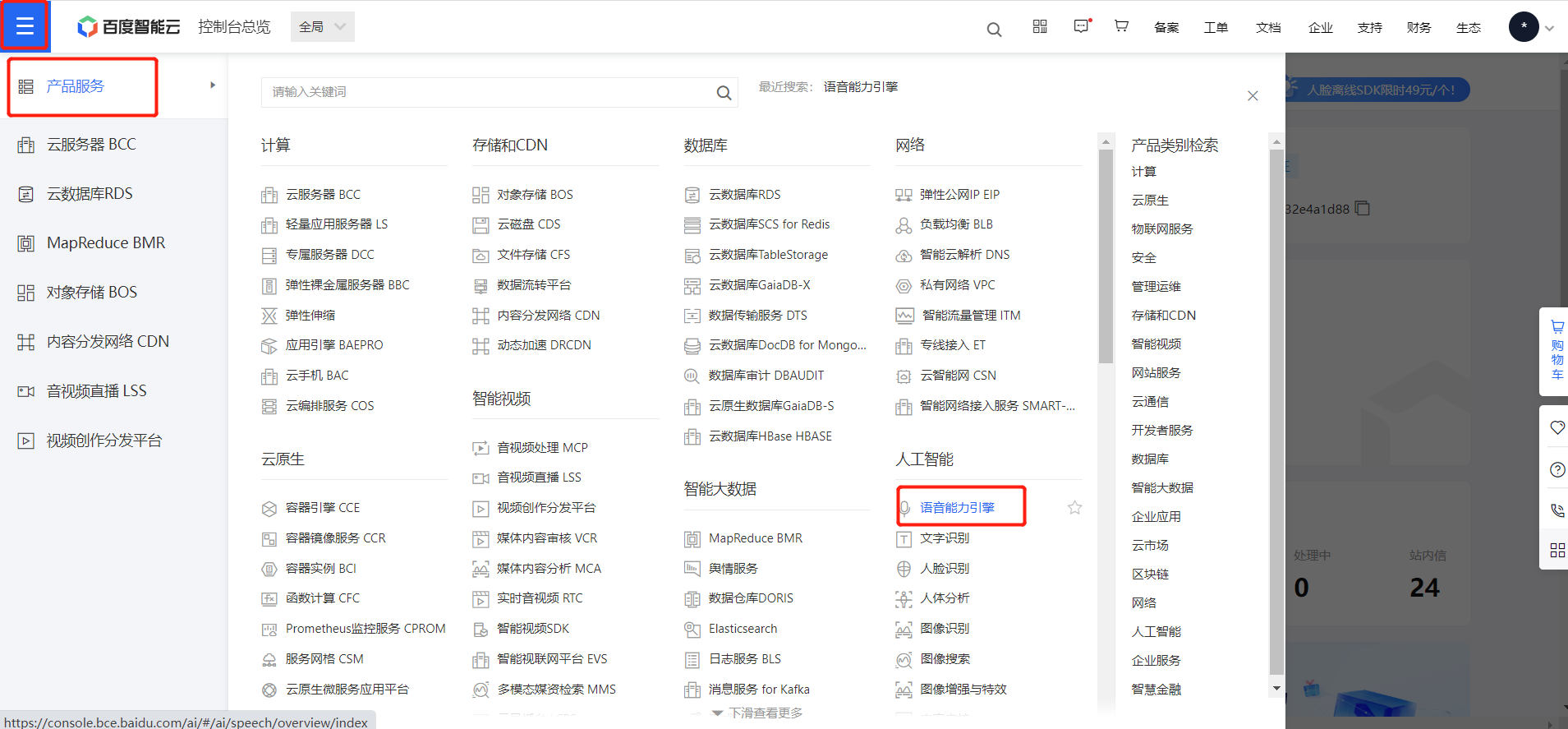
3.登陆后,点击右上角控制台按钮,找到语音能力引擎
4.语音能力引擎控制台首页,找到资源免费领取入口,需要完成实名认证后,就可以免费领取所有语音识别和语音合成服务

5.创建应用,左侧导航栏点击应用列表->创建应用,配置如下

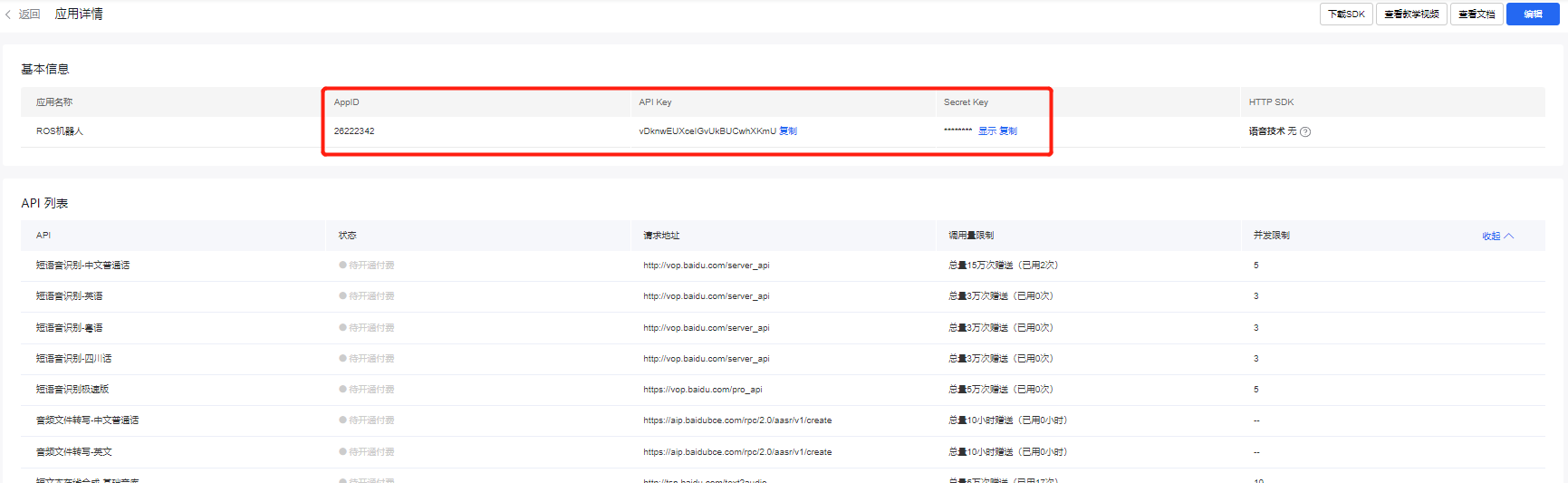
6.查看token,点击进入应用详情页即可查看,红框中的信息将在项目中进行替换
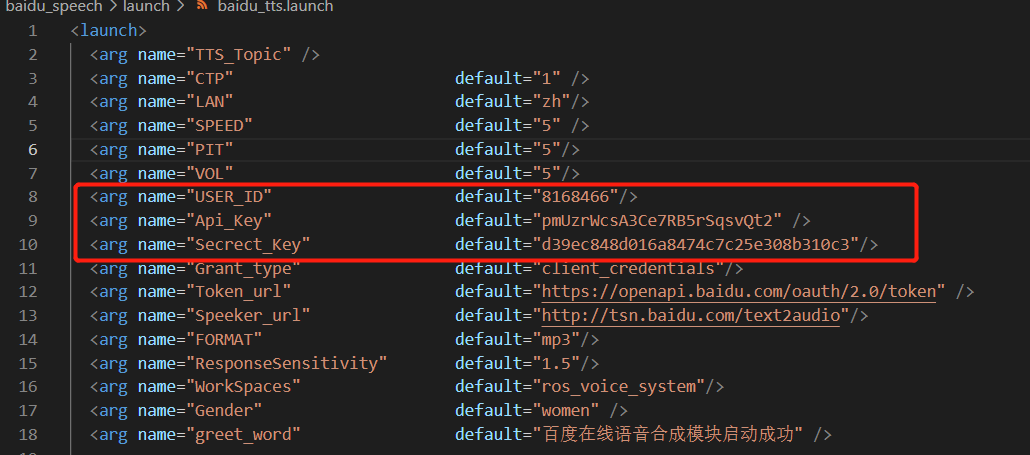
7.找到项目中baidu_asr.launch和baidu_tts.launch启动文件,将参数配置中的ID,Api,Secrect进行替换,即可调用自己刚才申请的服务,更换后执行roslaunch voice_bringup voice_bringup.launch 重启项目
以上是百度语音引擎服务配置的过程,源代码默认使用的科大讯飞语音服务引擎,大家可以体验自己申请百度智能云服务,替换科大讯飞服务引擎。
科大讯飞开放平台:https://www.xfyun.cn/
如果想申请自己的科大讯飞语音服务引擎,大致过程一致,需要申请语音识别和语音合成服务,不同的是,需要在平台下载对应的SDK和AppID和在项目对应上,也就是说每个人SDK和AppID一一对应,仅替换AppID会出现(Recognizer error 10407)这个错误。

下载sdk压缩包后,进入Linux_iatxxx_xxxxxxxx/libs/x64 下(64位选“x64”,32位选”x86“),将libmsc.so文件复制到虚拟机HOME目录下,如图:

打开终端执行,将libmsc.so复制到/usr/local/lib/目录下,一定在复制完so文件后,执行sudo ldconfig。
执行完,再次运行例行程序,测试成功。
1 | sudo cp /home/ros/libmsc.so /usr/local/lib/ |
图灵机器人开放平台:http://www.tuling123.com/
也可以申请自己专属的机器人,但是目前该开放平台不提供免费的体验资源,并且每天调用量有限
探索发现
项目跑起来以后还能做什么?
Idea1:自定义唤醒词
Idea2:基于现有功能,实现连续对话
Idea3:基于知识图谱自定义某领域语音问答功能
前期准备
VMware下载:
VMware14
链接:https://pan.baidu.com/s/1lrNwuUpmmFtRwnlUEim5RA
提取码:xqq0
密钥
FF31K-AHZD1-H8ETZ-8WWEZ-WUUVA
CV7T2-6WY5Q-48EWP-ZXY7X-QGUWD
VMware16(win10及以上版本建议装此版本)
链接:https://pan.baidu.com/s/1TQsTNVJqiPCnvVKIeY-UAg
提取码:fu6u
密钥
ZF3R0-FHED2-M80TY-8QYGC-NPKYF
YF390-0HF8P-M81RQ-2DXQE-M2UT6
ROS+Ubuntu16.04镜像(VMware):
初始化用户名:ros 密码:123456
链接:https://pan.baidu.com/s/1WORFJfr_llFCmywyNzVAZw?pwd=j2p2
提取码:j2p2
语音交互源代码下载
链接:https://pan.baidu.com/s/13nqlBSbhp8kZfVrlB1nJVg
提取码:1lyq
VMware Tools的安装
最大的好处是可以直接把windows界面的文件拖进linux虚拟机内
方法参考:https://blog.csdn.net/Williamcsj/article/details/121019391
重新启动虚拟机中的Ubuntu系统
将源代码文件夹压缩包ros_voice_system-master.tar.gz,复制到虚拟机/home目录下
1 | cd /home/ros/ |
解压操作也可以通过图形化界面,右键,提取压缩包中的文件
添加声卡
操作如下图所示,添加->声卡->完成
系统启动
安装语音相关软件包
打开一个终端执行脚本
1 | cd /home/ros/ros_voice_system-master/scripts |
此脚本安装缺少运行语音程序的软件包,编译整个代码空间,配置环境变量,可以说是一键执行脚本,减少大家烦琐的配置编译步骤。
执行过程中的warring提醒pip版本可用更新,请不予理会,pip更新后会导致版本不兼容
该过程根据网络情况不同,耗时10-40分钟
脚本运行结束后
编译启动
脚本已经相当完善,包含了环境变量配置,编译和启动功能,如需编译和启动参考以下命令
编译需要在ros工作空间根目录下执行,也就是在ros_voice_system-master
1 | catkin_make |
启动命令
1 | source devel/setup.bash |
在没有出现错误的前提下,如果唤无法唤醒,请一定要检查输入音量,不要设置过低,Ubuntu默认设置可能很低
如何还无法唤醒也不要着急,此代码有两套语音唤醒方案,后面会教大家如何更换配置。
如果现在就想唤醒体验一下,也可以暂时通过命令行唤醒,首先打开一个新终端,执行一下命令
1 | rostopic pub /voice_system/wakeup_topic std_msgs/String "data: '卡丁'" |
程序解读
该项目一共包含11个功能包,一般情况下只需修改launch和src目录下的代码文件
修改voice_bringup.launch 启动文件
该launch文件为ROS下语音系统的总启动文件,当运行加载启动后会自动的来启动语音唤醒,语音识别,语义理解,语音合成节点。需要注意的是这 里由于实现方案较多,现在实现的所有语音功能唤醒模块有sphinx和snowboy,语音识别用百度在线语音识别和科大讯飞在线语音识别功能实现,语义解析目前使用图灵机器人的在线语义解析实现,对于语音合成功能使用百度在线语音和科大讯飞在线语音合成实现,所有可用的节点都会在launch文件中列出,但是并不是所有节点都启动,若想启动相应节点去掉注释即可,因此现在规定 默认的启动节点如下所列:
1.语音唤醒(WakeUp):pocketsphinx离线语音唤醒,唤醒词:卡丁
2.语音识别(ASR):科大讯飞在线语音识别功能;
3.语义处理(NLP):图灵机器人在线语义处理;
4.语音合成(TTS):科大讯飞在线语音合成模块;
比如语音识别功能,配置了两套方案,如果选用科大讯飞语音识别(iflytek_asr),就需要把百度语音识别(baidu_asr)注释掉,避免冲突,其他功能配置方法同理
服务调用配置
目前启动起来的语音服务并不是使用的自己的配置,随时都有欠费停用的风险,一般开发平台新用户完成实名认证会有免费资源调用额度,以百度语音引擎为例,介绍配置过程
1.打开百度智能云官方网站https://cloud.baidu.com/
2.如果没有百度账号,需要先注册一个账号
3.登陆后,点击右上角控制台按钮,找到语音能力引擎
4.语音能力引擎控制台首页,找到资源免费领取入口,需要完成实名认证后,就可以免费领取所有语音识别和语音合成服务
5.创建应用,左侧导航栏点击应用列表->创建应用,配置如下
6.查看token,点击进入应用详情页即可查看,红框中的信息将在项目中进行替换
7.找到项目中baidu_asr.launch和baidu_tts.launch启动文件,将参数配置中的ID,Api,Secrect进行替换,即可调用自己刚才申请的服务,更换后执行roslaunch voice_bringup voice_bringup.launch 重启项目
以上是百度语音引擎服务配置的过程,源代码默认使用的科大讯飞语音服务引擎,大家可以体验自己申请百度智能云服务,替换科大讯飞服务引擎。
科大讯飞开放平台:https://www.xfyun.cn/
如果想申请自己的科大讯飞语音服务引擎,大致过程一致,需要申请语音识别和语音合成服务,不同的是,需要在平台下载对应的SDK和AppID和在项目对应上,也就是说每个人SDK和AppID一一对应,仅替换AppID会出现(Recognizer error 10407)这个错误。
下载sdk压缩包后,进入Linux_iatxxx_xxxxxxxx/libs/x64 下(64位选“x64”,32位选”x86“),将libmsc.so文件复制到虚拟机HOME目录下,如图:
打开终端执行,将libmsc.so复制到/usr/local/lib/目录下,一定在复制完so文件后,执行sudo ldconfig。
执行完,再次运行例行程序,测试成功。
1 | sudo cp /home/ros/libmsc.so /usr/local/lib/ |
图灵机器人开放平台:http://www.tuling123.com/
也可以申请自己专属的机器人,但是目前该开放平台不提供免费的体验资源,并且每天调用量有限
探索发现
项目跑起来以后还能做什么?
Idea1:自定义唤醒词
Idea2:基于现有功能,实现连续对话
Idea3:基于知识图谱自定义某领域语音问答功能
讨论区
https://gwzone.cn/articles/2022/12/01/ROS%E8%AF%AD%E9%9F%B3%E4%BA%A4%E4%BA%92%E5%AE%9E%E7%8E%B0/
如有问题,各种运行错误,欢迎在最下面的讨论区讨论
- 本文标题:ROS语音交互实现
- 本文作者:HaoHao Guo
- 创建时间:2022-12-01 03:14:20
- 本文链接:https://gwzone.cn/articles/2022/12/01/ROS语音交互实现/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!